简介
作于2023年4月22日。修订和重新发布于2024年9月16日。
整理了 CodeBert 相关的知识点,部分梳理了自 Word2Vec以来的NLP-AI模型发展历史。
(不精彩,流水账)
Talk 讲解(很好!):
CodeBERT: 面向编程语言的预训练模型- TechBeat
0.GPT 总结

1. BERT前后的NLP发展史
| 时间 | 名称 |
|---|---|
| 2013 Jan | Word2Vec |
| 2014 Jan | Glove |
| 2016 July | Fasttext |
| 2018 Feb | ELMO |
| 2018 Octo | BERT |
| 2019 Jan | Transformer-XL |
| 2020 Feb | GPT-2 |
| 2022 Novb | GPT-3.5 |
2.BERT的特点:
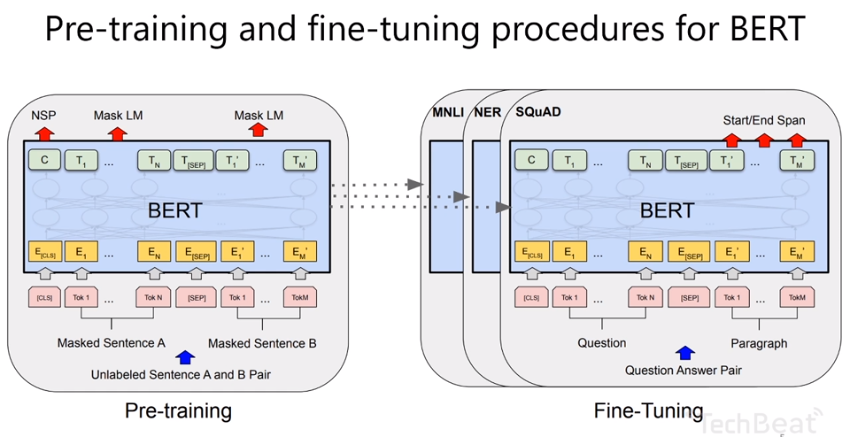
BERT使用了如GPT所说的”MLM” masked language model 遮蔽语言模型和代码文本分类任务 CTC的思路.
MLM遮蔽语言模型是说训练之前,会把一个sentence里的少量token 随机遮蔽掉,然后让模型去猜这个token是什么, 做一个 self-supervised training. 这样可以加强模型的语义理解和预测能力.
CTC就是给每个sentence增加一个分类的token [CLS] 通过它做一个二元分类.
也就是说,这个Sentence是正向语义还是负面语义,我们可以通过token cls 来判断.
此外,还在两个sentence之间加了 [SEP] 分隔符token.
这样,允许我们在多个 sentence的时候,组合 12句子,23句子,13句子,有多重语义. 造出了多个 sentence pair. 用cls建模两句话的关联,并作二元分类.
预训练和fine-tuning是有紧密关系的. 比如判断情感极性,那用cls token就行了.
序列标记,底层都是bert,上层
bert可以应用大规模数据,下游应用有一个uniform 的base。
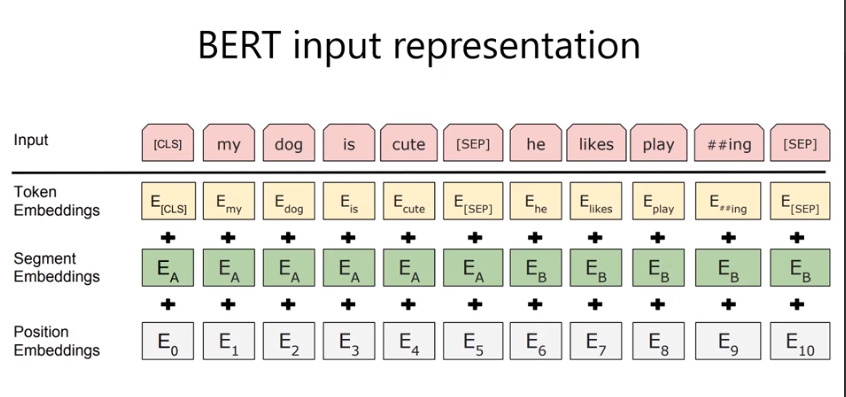
input 表示:
playing 分成2个word piece.
##ing 表示是follow 前面的token.
Embedding特点:
token embedding :本身token的词义
segment: 整个语句的语义.两句话合起来 做sentence pair的classification很有意义.
position: transformer需要的 位置参数. 解决长程依赖.
3. BERT benchmark
SQuAD benchmark 斯坦福 直接提交. BERT 是 2018年的SOTA
GLUE上, BERT也是九项指标的第一.包括CoLA SST-2 MRPC STS-B QQP RTE QNLLI等
4. BERT影响
BERT是一个划时代的研究.
它是NLP领域的大脑. 而不是一个应用层的模型.
所以叫他 pre-training model.
具体的应用层还需要下游的fine-tuning 也就是领域知识的微调.
在2019年, 出现了大量基于BERT的 多模态工作.
archive上
单模态到多模态.
5.关于CodeBert
属于一种双模态.
自然语言和编程语言双向映射的工作.
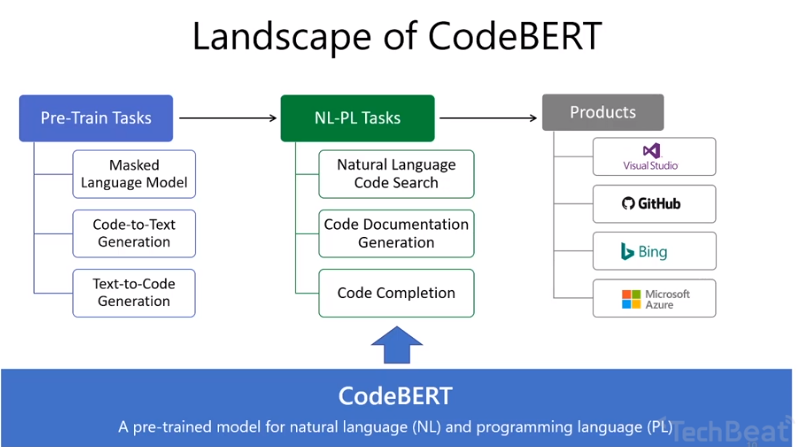
预训练: 有code和text的pair 可以做预训练.
有了预训练模型,可以支持下游应用.
function 生成comment.
code completion 补全.
code search github和StackOverflow的检索.
6. Motivation
Code Search
7.CodeBert的Architecture

方法1: masked language model.
train的时候用同一个mask.
在第一个loss里,只用到了 text-code 这种data.
有很多code,没有text. 想用起来
motivation: google
方法2: Replaced Token Detection
elector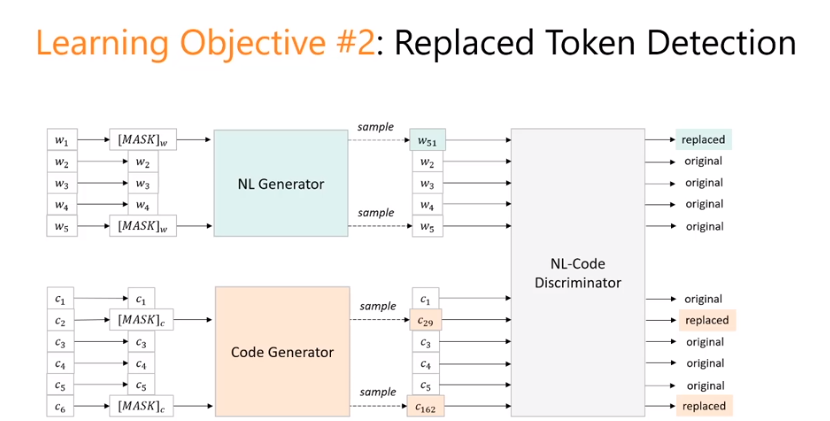
随机 mask token.
generator. 对masked token做猜测生成. 可以用GPT transformer这些做.
discriminator. 判断generator生成的token 和 origin token的区别. 二分类任务. Category比较少, 容易分类. Softmax 好做.
没有train 一个heavy的model.
没有做的很复杂.
generator 没有和 discriminator 一起training.
8. 数据集
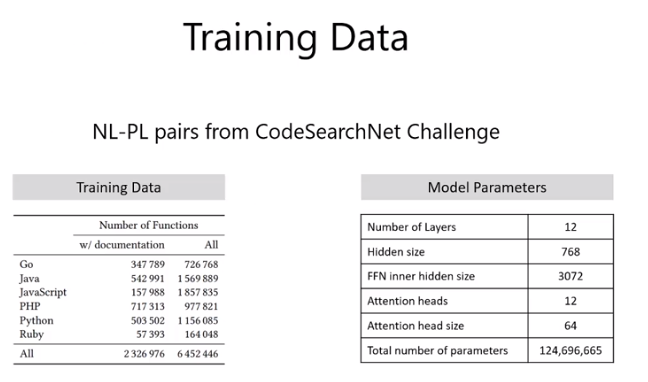
2.3 M 各种语言 code-text pair.
9. 指标和应用
Code Search:
Learning Curve: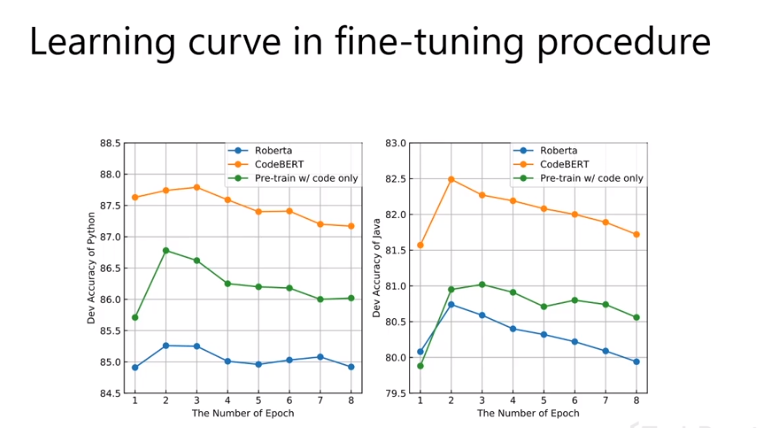
Code to text.
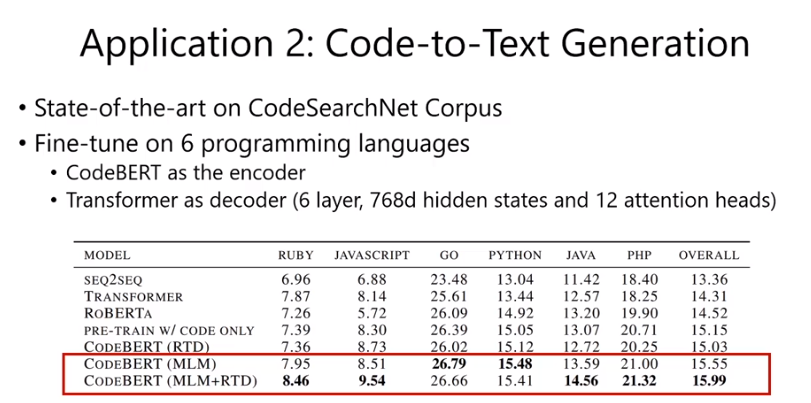
Encoder: CodeBERT
Decoder: 接了一个Transformer
- 泛化能力
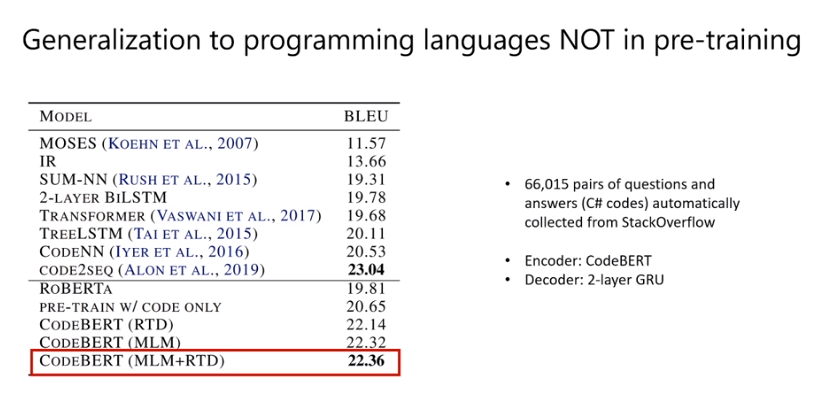
泛化能力: 对没有学习过的语言 C#
Encoder: CodeBERT
Decoder: 2-layer GRU
没有使用AST.
学到了语言通用的东西.
- Probing.
pre-training 效果不错,是fine-tuning好,还是pre-training就做的很好.
特朗普女儿伊万卡. 知识.
写一个女儿的描述形式. 需要写 pattern. 给Ivanka 和 Daughter Father 这些词汇,能不能 涌现出来Trump这些.
指标: max min less greater.
masked 一个 token. 把min mask掉, 然后用Robert 和CodeBERT 分别预测.
没听懂.
10.总结
提出了模型 CodeBERT. 多语言的预训练模型. 在 code search code-to-text上很不错.
为了检测在不做fine-tuning的情况下, pre-training model的能力, 作者们还提出了一个NL-PL probing的验证用dataset.